Google Gemini生成的摘要
一、背景
身处信息时代之中,我们最能明显感受到的一点就是密集数据大量爆发,人们积累的数据也越来越多。这些庞杂的数据出现在一起,传统使用的很多数据记录、查询、汇总工具并不能满足人们的需求。更有效的将这些大量数据处理,让计算机听懂人类需要的数据效果,从而形成更加自动化、智能的数据处理方式。
为了处理这些海量数据,出现了各种大数据引擎、搜索引擎、计算引擎、3D引擎等,用以更好解决数据庞杂带来人工无法处理的问题。而作为其中比较常用的就是Excel的计算公式引擎,本文主要是讲解计算引擎的前端实现方案。
二、核心问题
- 核心需求点:满足用户对表格数据的逻辑比较、逻辑运算和统计需求。
- 核心问题:1.建立表格各类区域和公式之间的复杂依赖关系并得到合理的计算更新顺序。2.公式字符串的词法解析生成结构化数据
三、功能分析
对于核心问题第一点来说,可以在以下两个资料中,学习到一些思想方法。
核心问题第二点:
如图,A8单元格的字段中存在一个公式SUM(1,5.512,B1,A1),formula记录了两个信息,其中的10是公式表达式的索引,22、23是公式表达式中包含的引用位置的索引:
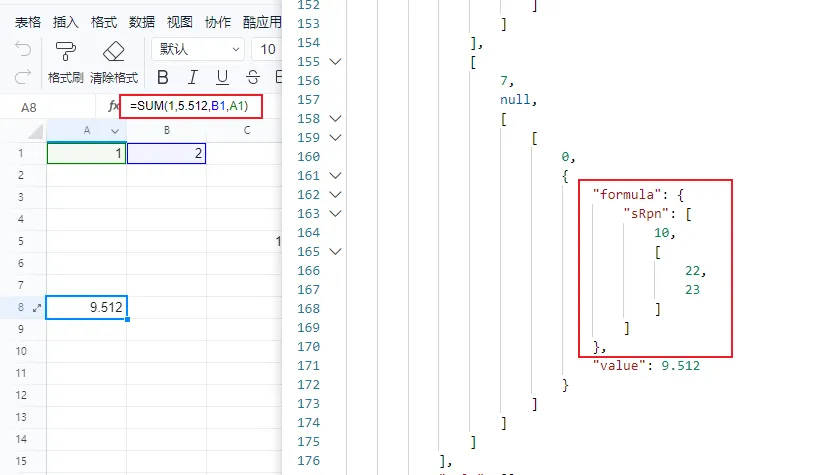
在元数据部分可以看到对应的数据:
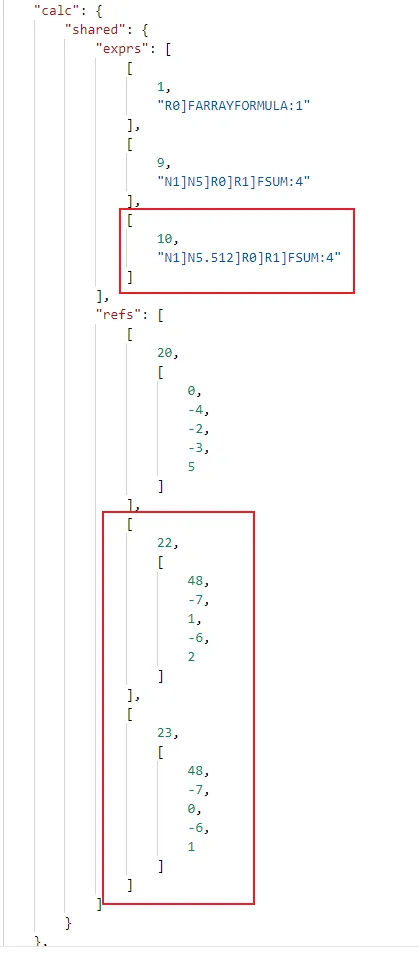
exprs中的是表达式的模板,如果存在两个公式表达式只有引用位置不同,那它们共用一个模板:
refs中的即是引用位置,通过相对位置进行表示:(位置引用和公式字符串的转化关系参考这里)
由此可见钉钉表格完整的公式表达式由表达式模板(expres)+引用位置(refs)组合得出。
通过单元格上formula记录的索引,找到对应的表达式模板和引用位置,就能够完整表达整个公式。
公式之间的依赖关系并没有通过快照存储,需要在表格初始化时进行构建。
四、概要设计
公式的基本原理
在工作表中可以使用常量和算术运算符创建简单的公式。
公式以输入“=”开始。
复杂一些的公式可能包含函数和常量。
函数:函数是预先编写的公式,可以对一个或多个值执行运算,并返回一个或多个值。函数可以简化和缩短工作表中的公式,尤其在用公式执行很长或复杂的计算时。
常量:不进行计算的值,因此也不会发生变化。
基本功能:
- 可以进行+、-、、四则运算等计算
- 可以引用其他单元格中的数据。
- 可使用文本字符串,或与数据相结合。
- 可运用>、<之类的比较运算符比较单元格内的数据。
- 不仅可以用于公式的计算,还可以运用于其他情况中。
位置引用:
- A1 相对引用
- $A1 绝对引用列
- A$1 绝对引用行
- $A$1 绝对引用行和列
下面将介绍公式功能的基本实现原理。
公式的组成部分
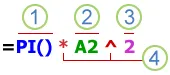
- 函数:PI() 函数返回 pi 值:3.142…
- 引用:A2 返回单元格 A2 中的值。
- 常量:直接输入到公式中的数字或文本值,例如 2。
- 运算符:^(脱字号)运算符表示数字的乘方,而 *(星号)运算符表示数字的乘积。
公式中使用常量
常量是一个不是通过计算得出的值;它始终保持相同。
例如,日期 10/9/2008、数字 210 以及文本“季度收入”都是常量。
表达式或从表达式得到的值不是常量。
如果在公式中使用常量而不是对单元格的引用(例如 =30+70+110),则仅在修改公式时结果才会变化。
通常,最好在各单元格中放置常量(必要时可轻松更改),然后在公式中引用这些单元格。
公式中使用引用
引用的作用在于标识工作表上的单元格或单元格区域,并告知 程序 在何处查找要在公式中使用的值或数据。
你可以使用引用在一个公式中使用工作表不同部分中包含的数据,或者在多个公式中使用同一个单元格的值。
还可以引用同一个工作簿中其他工作表上的单元格和其他工作簿中的数据。
引用其他工作簿中的单元格被称为链接或外部引用。
A1 引用样式
默认情况下,程序 使用 A1 引用样式,此样式引用字母标识列(从 A 到 XFD,共 16,384 列)以及数字标识行(从 1 到 1,048,576)。 这些字母和数字被称为行号和列标。要引用某个单元格,请输入列标,后跟行号。
例如,B2 引用列 B 和行 2 交叉处的单元格。若要引用 用途 A 和行 10 交叉处的单元格 A10 在列 A 和行 10 到行 20 之间的单元格区域 A10:A20 在行 15 和列 B 到列 E 之间的单元格区域 B15:E15 行 5 中的全部单元格 5:5 行 5 到行 10 之间的全部单元格 5:10 列 H 中的全部单元格 H:H 列 H 到列 J 之间的全部单元格 H:J 列 A 到列 E 和行 10 到行 20 之间的单元格区域 A10:E20 引用同一工作簿中另一个工作表上的单元格或单元格区域
下例中,AVERAGE 函数将计算同一个工作簿中名为 Marketing 的工作表的 B1:B10 区域内的平均值。
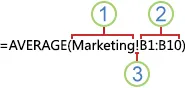
1、对名为 Marketing 的工作表的引用
2、引用 B1 到 B10 的单元格区域
3、感叹号 (!) 将工作表引用与单元格区域引用分开绝对引用、相对引用和混合引用之间的区别
相对引用 公式中的相对单元格引用(如 A1)是基于包含公式和单元格引用的单元格的相对位置。 如果公式所在单元格的位置改变,引用也随之改变。 如果多行或多列地复制或填充公式,引用会自动调整。 默认情况下,新公式使用相对引用。 例如,如果将单元格 B2 中的相对引用复制或填充到单元格 B3,将自动从 =A1 调整到 =A2。
复制的公式具有相对引用:
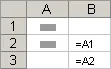
绝对引用 公式中的绝对单元格引用(如 $A$1)总是在特定位置引用单元格。 如果公式所在单元格的位置改变,绝对引用将保持不变。 如果多行或多列地复制或填充公式,绝对引用将不作调整。 默认情况下,新公式使用相对引用,因此您可能需要将它们转换为绝对引用。 例如,如果将单元格 B2 中的绝对引用复制或填充到单元格 B3,则该绝对引用在两个单元格中一样,都是 =$A$1。
复制的公式具有绝对引用:
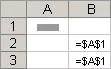
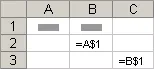
混合引用 混合引用具有绝对列和相对行或绝对行和相对列。 绝对引用列采用 $A1、$B1 等形式。 绝对引用行采用 A$1、B$1 等形式。 如果公式所在单元格的位置改变,则相对引用将改变,而绝对引用将不变。 如果多行或多列地复制或填充公式,相对引用将自动调整,而绝对引用将不作调整。 例如,如果将一个混合引用从单元格 A2 复制到 B3,它将从 =A$1 调整到 =B$1。
复制的公式具有混合引用:
公式的词法分析


语法分析
公式的语法分析使用开源库jison库,我们需要编写定义相关的语法规则,使用命令生成解析器。Jison 解析器会根据定义的语法规则对输入进行解析,并构建一个语法树。
首先,你需要使用 Jison 定义函数表达式的语法规则。这可以通过编写一个称为”Jison 文法”的规则文件来完成。Jison 文法使用类似于 BNF(巴科斯范式)的语法来描述语法规则。例如,下面是一个简单的 Jison 文法示例,用于解析简单的数学函数表达式:
1 | |
语法树
语法树是一个表示函数表达式结构的树状数据结构。每个节点代表一个语法规则的实例,例如函数调用、运算符、变量等。
例如:一个简单的数学表达式:2 + 3 * (4 - 1)可以解析成
1 | |
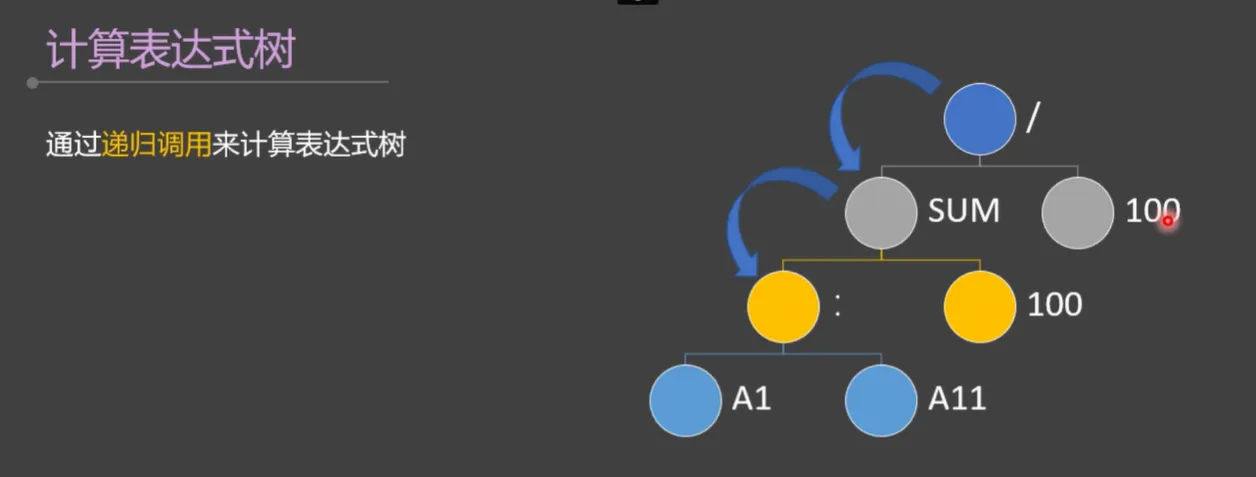
计算表达式
计算表达式使用了开源库formula.js。
该开源库能够支持三百多种函数的运算,但不支持 excel 中数组公式的计算,例如”=A:C+1”,需要对其 IF 函数、加、减、乘、除等运算规则进行修改,使其支持参与运算的因子是数组的情况。
公式的相互依赖
公式可以存在单元格引用,而被引用的单元格值可能也是由公式计算得到的,例如: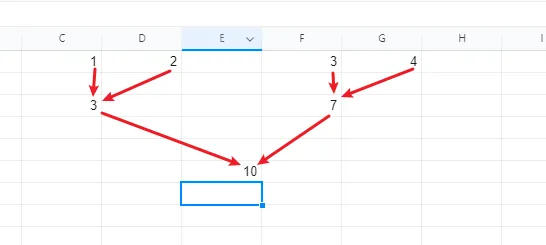
C3 上的公式是=SUM(C1:D1),F3 上的公式是=SUM(F1:G1),E6 上的公式是=SUM(C3,F3).
如果我们将 C1 的值更新,依赖 C1 的 C3、依赖 C3 的 E6 需要重新计算并更新公式结果,并且根据依赖关系,必须先更新 C3 再更新 E6。
五、详细设计
假设在 A1 单元格位置键入以下公式
1 | |
首先我们在单元格数据里记录公式信息/公式 ID(此处举例为“A”)
1 | |
另外,我们还需要在文档数据里更新公式信息,以及对应的引用区域。格式如下
1 | |
1 | |
公式的还原方法
在实际的应用程序中,我们还需要还原公式用以展示和编辑。
由于存在 相对引用 和 绝对引用,以及 混合引用 的场景,这使得引用位置的还原变得复杂。
我们通过 type 字段记录相关的位置信息,在还原时配合 ref 结构中的 type 字段,可以准确还原位置引用。
|
对于正在复制的公式: |
如果引用是:A1= |
它会更改为:C3= |
|
|
$A$1(绝对列和绝对行) |
$A$1(引用是绝对的) |
|
A$1(相对列和绝对行) |
C$1(引用是混合型) |
|
|
$A1(绝对列和相对行) |
$A3(引用是混合型) |
|
|
A1(相对列和相对行) |
C3(引用是相对的) |
钉钉:使用 type 的二进制数字表示所有不同位置的$符号
| TYPE | 含义 |
|---|---|
| -1 | 被删除的引用 |
| 0(00) | A1 |
| 1(01) | A$1 |
| 2(10) | $A1 |
| 3(11) | $A$1 |
| 4(100) | 1:1 |
| 5(101) | 1:$1 |
| 6(110) | $1:1 |
| 7(111) | $1:$1 |
| 8(1000) | C:D |
| 9(1001) | C:$D |
| 10(1010) | $C:D |
| 11(1011) | $C:$D |
| 16(10000) | A1:B1 |
| 17(10001) | A1:B$1 |
| 18(10010) | A1:$B1 |
| 19(10111) | A1:$B$1 |
| 20(10100) | A$1:B1 |
| 21(10101) | A$1:B$1 |
| 22(10110) | A$1:$B1 |
| 23(10111) | A$1:$B$1 |
| 24(11000) | $A1:B1 |
| 25(11001) | $A1:B$1 |
| 26(11010) | $A1:$B1 |
| 27(11011) | $A1:$B$1 |
| 28(11100) | $A$1:B1 |
| 29(11101) | $A$1:B$1 |
| 30(11110) | $A$1:$B1 |
| 31(11111) | $A$1:$B$1 |
我们也采用相同的做法。
可以看到 四种类型的区域 可以定四个不同的基数 0,4,8,16。
区域格式为$A$1,词法分析出单元格类型,则基数为 0,第一二个数字前面有$,type=0+1+2=3,二进制后四位 0011
区域格式为$A1:$B$1,词法分析出矩形区域类型,则基数为 16,第 1 第 3 第 4 字符前有$,type = 16+8+2+1=27,二进制后四位 1011
通过先判断 type 值的范围,确定出区域类型,得到基数。
其中二进制值去掉基数之后 1 的位数就是$符号出现的位置。
最后就能通过 [$符号位置、range、区域类型] 三个信息反推出原公式。
公式的链路计算
假设存在以下公式
A = B
C = A
D = A+B
E = A + B + C + D
B = A
注:红色公式会导致依赖链路成环。
基于上述公式信息,我们可以构建如下依赖关系。
[
{ id: ‘b’, dep: [ ‘a’, ‘d’, ‘e’ ] },
{ id: ‘a’, dep: [ ‘c’, ‘d’, ‘e’, ‘b’ ] },
{ id: ‘c’, dep: [ ‘e’ ] },
{ id: ‘d’, dep: [ ‘e’ ] }
]
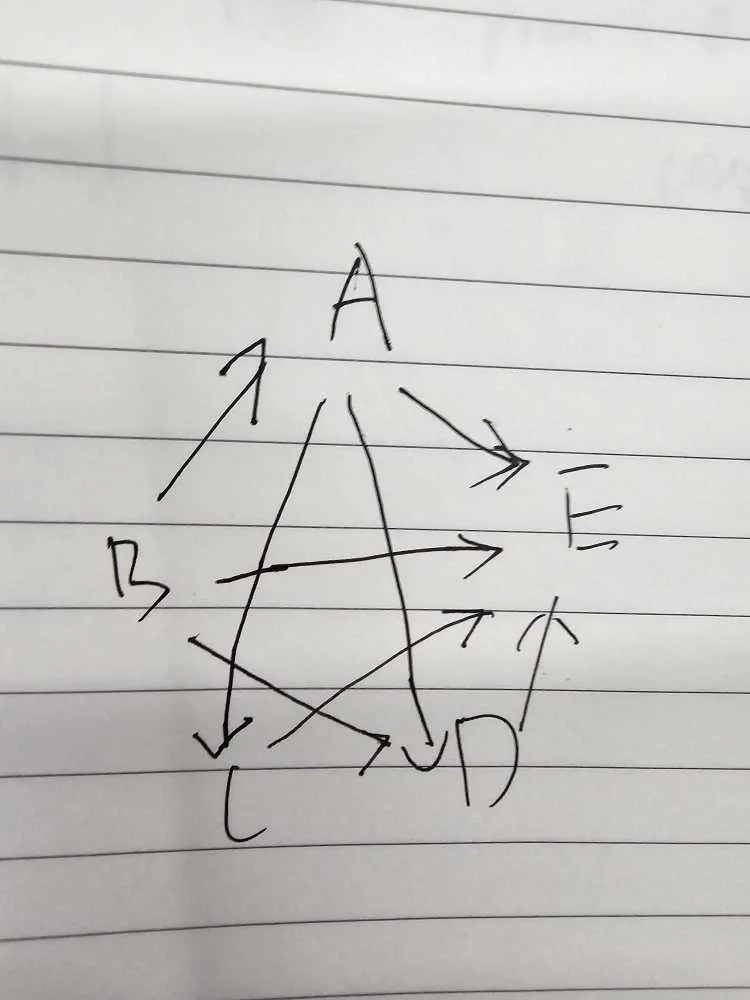
当 B 节点数据变更之后,我们需要递归更新上游链路的所有节点。
更新逻辑如下:
1、清空更新链路
2、查询变更节点的上游
1 | |
发现 path 中的数据 b 不在 next 里(没有入度),则添加 b 到更新链路中(此时更新链路为 [b])。
此处的检查是为了保证更新顺序(最小入度)。
对 next 去重后重复查询上游节点。
3、递归查询变更节点的上游
1 | |
发现 path 中的数据 a 不在 next 里(没有入度),则添加 a 到更新链路中(此时更新链路为 [b, a])。
这里需要注意的是,如果 next 中的节点存在于更新链路中,则出现循环依赖,递归终止。
如果开启 N 次迭代计算,就使用当前的更新链路[b,a]进行 N 次重复计算。否则 b 和 a 所在的单元格就需要报引用错误。
如果 B = A 不存在(依赖成环),则重复上述步骤。
对 next 去重后重复查询上游节点。
1 | |
发现 path 中的数据 c,d 不在 next 里(没有入度),则添加 c,d 到更新链路中(此时更新链路为 [b, a, c, d])。
对 next 去重后重复查询上游节点。
1 | |
发现 path 中的数据 e 不在 next 里(没有入度),则添加 e 到更新链路中(此时更新链路为 [b, a, c, d, e])。
至此,公式递归完毕,按照更新链路依次更新单元格数据即可。
公式的冲突处理
由于存在冲突的情况:假设两个客户端基于同一个版本进行了不同的编辑操作,两种操作发生了冲突,没有经过冲突处理之前,两个客户端得到的计算结果都不是正确的。
因此,在发生公式编辑操作时,前端不会将计算结果进行上发到服务端,而是等到后端处理完op冲突收到op后,再进行计算结果。
公式的初始化
如果服务端快照不存储计算结果,服务端也没有计算能力的话,就需要前端在表格初始化时,进行一次全局公式计算。
如何进行初始化全局计算?
由于上方描述的算法是基于某个节点出现变更,再生成该节点变更之后需要更新的节点链路。项目初始化时就需要先得到入度最小的节点,并由该节点作为函数调动的发起者,得到完整的更新链路。然后再对更新链路中含有公式的单元格进行依次计算更新。
如何得到入度最小的节点?
表格初始化先使用快照model的单元格数据,转化成前端表格数据表。然后对前端表格数据表进行遍历,依据快照中的ref formula构建依赖图,在创建依赖图的方法中添加回调使用Map记录id出现次数。等数据初始化完毕,出现次数最少的节点即为入度最小的节点此案例为B)
进阶:
- 使用Web Worker,实现多线程计算?
- 采用C、C++、Rust实现编译代码, 使用WASM实现更好的计算速度?
- 服务端运算的支持?
参考阅读

AquaHydro
望穿他盈盈秋水,蹙损他淡淡春山。